
그래프 데이터 모델은 현실 모형에 가까운 직관적인 형태의 “데이터 모형”을 제공합니다. 현실과 가까운 모습의 데이터 모델로 데이터가 운용되고 데이터 모델의 변형이 자유롭기 때문에 기존 관계형 데이터보다 더 효율적이며 직관적입니다. 최근 빠른 시장 변화에 따라, 데이터의 보유 규모뿐만 아니라 데이터의 숨은 가치를 바로 알고 이를 유용하게 활용하는 것이 점점 더 중요해지고 있습니다. 이러한 점에서 그래프 데이터베이스(이하 그래프 DB)의 직관적인 데이터 모델링은 실제 조직의 데이터 모델과 흡사한 데이터 모델링이 가능하며, 이를 통해 조직 전체의 데이터 흐름을 쉽게 이해하고 활용하는 데 많은 도움을 줄 수 있습니다.
본 백서는 그래프 DB의 활용 방법을 소개하기 위해 제작되었으며, 1부는 그래프 모델링, 2부는 예측 분석에 대한 내용을 다루고 있습니다. 그래프와 그래프 DB에 대한 간략한 소개 후 그래프 모델링에 대해 설명합니다. 그래프 DB 구축 시 분석의 방향과 데이터에서 중요시하는 요소에 따라 모델링의 방법이 달라질 수 있습니다. 일반적으로 적용 가능한 방법론과 Kaggle에서 제공하는 Brazilian E-Commerce RDB 데이터셋을 그래프 DB로 변환하는 실제 예시를 기술했습니다.
그래프 모델링으로 변환하는 과정
1. RDB를 GDB로 변환하기
RDB에서 GDB로의 모델링 시 방향성은 RDB에서 중요시하는 변수를 중심으로 GDB 모델링을 진행하는 것도 하나의 좋은 출발점이 될 수 있습니다. 예를 들면, 은행에서 이상거래탐지(FDS)시 계좌를 중심 노드로 설정 후 필요한 변수를 입출금 프로세스에 맞춰 모델링이 가능합니다. 마찬가지로 이커머스 사이트에서는 거래(Order)를 중심으로 필요한 변수들을 나열하며 노드(node)와 엣지(edge)를 설정하는 것이 모델링의 한 방법이 될 수 있습니다.
브라질의 E-Commerce 플랫폼인 ‘Olist’의 데이터를 이용하여 실제로 분석 목적에 부합하는 GDB 모델링을 어떤 방식으로 수행하는지 예시를 들어 보도록 하겠습니다. Olist 사이트는 고객 및 판매자 정보, 상품, 주문, 배송, 리뷰 등과 관련된 정보를 갖고 있으며 데이터셋에 포함된 테이블, 변수와 각 테이블 간의 관계는 다음과 같습니다.
데이터를 RDB로 저장할 경우, 위 그림과 같이 복잡하게 얽혀있는 테이블에 key를 이용하여 매핑(mapping)해야 합니다.
소비자가 판매자로부터 상품을 주문하는 일련의 과정을 그래프로 표현하기 위해 이 과정에서 각 객체가 되는 소비자, 상품, 판매자, 주문을 각각 노드로 설정했습니다. 그리고 기준이 되는 행위인 ‘Order’가 Ego Node가 됩니다. 또한 하나의 주문에 다수의 상품과 판매자가 존재할 수 있습니다.
이렇게 설정한 각 객체의 관계를 엣지로 연결하였으며, 이를 도식화한 그림은 다음과 같습니다.
2. 속성(Property) 설정하는 방법
속성(Property) 설정에 앞서 데이터를 활용하여 수행하고자 하는 최종 목적에 대해서 알아보겠습니다. 우선 분석 목적에 맞춰 효율적으로 데이터를 추출할 수 있는 모델링이 필요합니다.
해당 데이터를 활용한 최종 분석 목적은 ‘배송시간 예측’으로 설정하였으며, 총 배송시간을 판매자가 상품을 발송할 때까지 걸리는 시간인 ‘Seller_Time’과 배송자가 상품을 고객에게 배송하는 데 걸리는 시간인 ‘Carrier_Time’으로 구분하였습니다. 또한, 탐색적 데이터 분석을 통해 다음의 특징들이 배송 시간에 영향을 미치는 것으로 판단하였습니다.
Seller_Time ← product_category(상품 카테고리), seller_id(판매자)
Carrier_Time ← product_category(상품 카테고리), distance(소비자-판매자 간 거리), freight_value(배송 운임)
1) Distance, Freight_Value
이제 Carrier_Time에 영향을 미치는 변수인 distance와 freight_value를 모델에 삽입해야 합니다. ‘Distance’는 ‘customer’와 ‘seller’ 간의 거리이므로 두 노드를 연결하는 엣지에 속성으로 설정하는 것이 직관적으로 타당할 것입니다.
그런데 이렇게 설정할 경우, Ego Node인 Order를 기준으로 조회할 때 여러 단계를 거쳐야 하며 이는 조회 시간 증가와 성능 저하의 이슈를 초래할 수 있습니다. 따라서 중심이 되는 ‘Order’를 기준으로 빠르게 조회할 수 있도록 Product와 Order Node 간 엣지에 속성으로 설정합니다.
위에서 말한 바와 같이 한 주문에 여러 개의 상품이 존재할 수 있기 때문에 이렇게 설정할 경우 같은 데이터가 중복으로 들어가는 상황이 발생할 수 있습니다. 그러나 그래프 DB의 특성상 여러 엣지에 속성을 설정하여 조회하는 것이 가능하기 때문에 이대로 진행하기로 하겠습니다.
2) Seller_Time, Carrier_Time
분석의 목적 변수가 되는 Seller_Time과 Carrier_Time의 모델링을 시작해보겠습니다.
첫 번째로 각 변수를 한 주문에서 파생되는 노드로 설정하는 방법이 있습니다. 이 경우, 새로운 배송 시간을 특정 노드로 분류하기 위하여 구간화 할 필요가 있으며, 새로운 주문에 대하여 배송 시간을 예측할 때 Classification 분석 모델이 필요하게 됩니다.
하지만 배송 시간의 경우 구간을 분류하는 것보다 시간을 ‘예측’하는 것이 본래의 목적에 더 부합합니다. 다른 노드로 설정하는 것보다 연속형 데이터 그대로 속성으로 삽입하는 것이 더욱 적절할 것입니다. 데이터에 ‘Order’를 기준으로 한 주문 당 하나의 배송 시간 정보가 있어서 ‘Order’ 노드의 속성으로 설정했습니다.
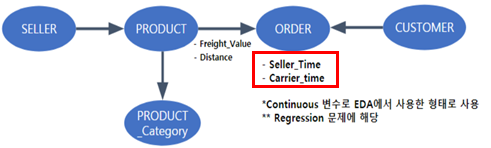
완성된 최종 GDB 모델은 다음과 같습니다.

G-PAS 실전편 2부 예고
2부에서는 예측분석에 사용할 수 있는 알고리즘을 설명할 예정입니다. 수많은 예측 분석 알고리즘을 소개하기엔 현실적으로 무리가 있다고 판단하여, Regression과 Classification에 대해 간략한 소개를 하고 Brazilian E-Commerce 사례에서 사용하였던 알고리즘을 기술할 예정입니다. Brazilian E-Commerce는 범주형 변수가 많아 범주형 변수가 많을 때 유용한 알고리즘을 설명하겠습니다.
글: 그래프 사이언스 R&D 센터
트렌디한 그래프 기술과 IT 소식을 뉴스레터로 받아보세요!
https://bitnine.net/ko/subscribe/
제품 및 기술문의
070-4800-3517 | agens@bitnine.net
'GRAPH DB > Graph Solution' 카테고리의 다른 글
| 그래프 기반 추천 시스템이란? (0) | 2022.03.21 |
|---|---|
| G-PAS 실전편 2부: 회귀와 분류로 알아보는 지도 학습 (0) | 2022.02.25 |
| G-PAS 이론편: 그래프 DB를 활용한 예측 분석 (0) | 2022.02.14 |
| G-PAS, 빅데이터 예측분석 시스템 (0) | 2020.12.21 |
| G-FDS, 이상행위 탐지의 최강자 (0) | 2020.11.13 |