
pgvector를 이용한 PostgreSQL vector 관리 및 분석 워크로드 기능확장 : FDS 시나리오 기반 활용 가이드
VectorDB 개요
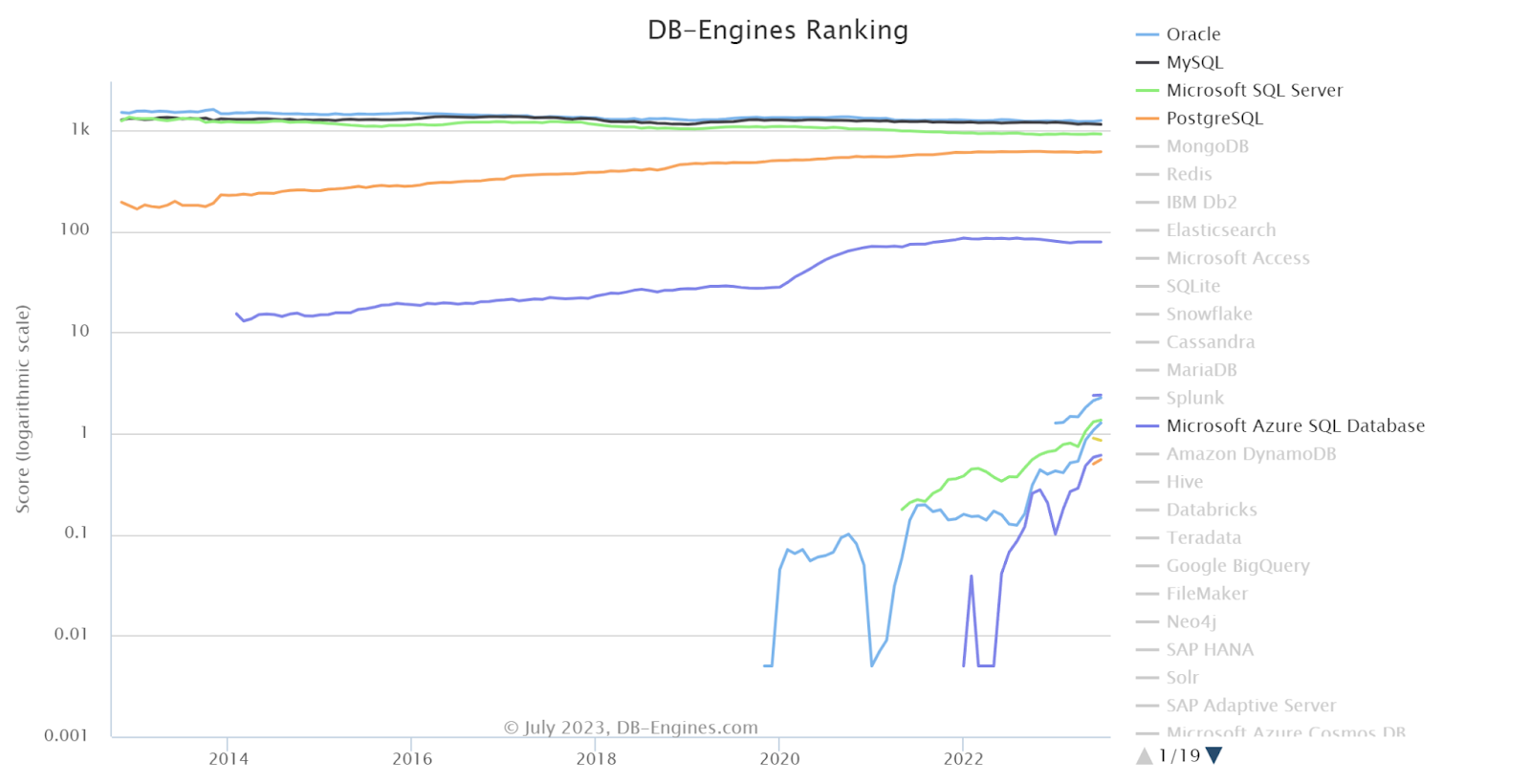
산업 전반적으로 AI의 영향이 커져감에 따라, AI의 결과물인 벡터의 관리에 대한 수요도 증가하고 있다. 그에 따라 VectorDB 니즈또한 증가하고 있음을 알 수 있다. 또한, 그림1의 차트에서 변동이 미미한 상단부 RDBMS 들과 다르게 2022년을 기점으로 DB 종합랭킹이 큰 폭으로 상승하고 있는 현황을 발견할 수 있다. 투자금액 뿐만아니라, DB 산업 내부적으로 많은 사용량이 발생하고 있기에, 지금은 VectorDB 시대라고 말해도 무리가 없을 정도로 대세의 길을 걷고 있다.
대세인 VectorDB, 그 작동원리와 장점은 무엇이기에 과연 인기를 받고 있을까? 개요와 5가지 구성요소에 대해 말해보자면 다음과 같다. VectorDB는 벡터 데이터베이스의 원칙에 기반하여 개발된 데이터베이스 시스템이다. 벡터 데이터베이스는 고차원 벡터 데이터를 저장, 검색, 분석하는데 특화된 기술을 제공하여 다양한 응용 분야에서 활용될 수 있으며, 다음과 같은 4가지 특징을 가지고 있다.
1. 벡터 기반 데이터 구조: VectorDB는 벡터 데이터를 중심으로 하는 새로운 데이터 구조를 제공한다. 각 데이터 요소는 고차원 벡터로 표현되며, 벡터의 차원은 사용자가 정의할 수 있다. 또한 벡터 기반 구조를 활용하여 복잡한 데이터 포인트 간의 유사성을 측정하고 비슷한 벡터들을 효율적으로 그룹화할 수 있다.
2. 벡터 인덱싱: VectorDB는 효율적인 벡터 인덱싱 기법을 사용하여 벡터 공간 내에서 빠르게 검색이 가능하며, 고차원 벡터 데이터를 기반으로 트리 구조나 해시 기반 인덱싱을 적용하여 데이터 검색 성능을 최적화하여 고차원 벡터 데이터일지라도 빠르게 검색할 수 있다.
3. 유사도 검색: VectorDB는 벡터 간의 유사성을 평가하고 유사도 기반 검색 기능을 가지고 있으며 , 코사인 유사도나 유클리드 거리 등의 유사성 측정 방법을 활용하여 가장 유사한 벡터들을 신속하게 검색할 수 있다.
4. 벡터 분석 기능: VectorDB는 벡터 데이터에 대한 통계 분석 및 패턴 인식 기능을 제공하며, 클러스터링, 차원 축소, 이상 탐지 등 다양한 벡터 분석 알고리즘을 지원하여 유용한 정보를 추출할 수 있다.
정리해보면 VectorDB는 고차원 벡터 데이터를 저장, 검색, 분석하는 벡터 데이터베이스 시스템이다. 벡터 기반 구조와 인덱싱 기법으로 데이터 검색을 빠르게 수행하며, 유사도 검색과 벡터 분석 기능을 지원한다.
PostgreSQL 개요
PostgreSQL은 오픈 소스 기반의 RDBMS로 ACID 트랜잭션과 ANSI SQL 표준 준수를 바탕으로 안정적인 데이터 관리와 다양한 고급 기능들을 제공하는 데이터베이스 시스템이다.
PostgreSQL은 ACID(원자성, 일관성, 고립성, 지속성) 트랜잭션을 제공하여 데이터의 안정성과 일관성을 보장한다. 또한 다양한 기능과 확장 가능성을 갖추고 있어서 대규모 엔터프라이즈 환경에서도 많이 사용한다. PostgreSQL은 ANSI SQL 표준을 준수하면서도 다양한 고급 기능을 제공한다.
PostgreSQL 테이블 형식의 주요 특징:
- 관계형 데이터 모델: PostgreSQL은 관계형 데이터베이스 시스템으로, 데이터를 테이블 형태로 구성한다. 각 테이블은 열(Column)과 행(Row)으로 구성되며, 열은 속성(Attribute)을 나타내고, 행은 레코드(Record)를 나타낸다. 이러한 구조를 활용하여 데이터 간의 관계를 정의하고 조작할 수 있다.
- 유연한 데이터 타입 지원: PostgreSQL은 다양한 데이터 타입을 지원한다. 기본적인 숫자, 문자열, 날짜 및 시간 타입부터 배열(Array), JSON, XML 등 다양한 형식의 데이터를 저장하고 처리할 수 있다. 또한 사용자 정의 데이터 타입을 생성하여 자신만의 복합적인 데이터 구조를 만들 수도 있다.
- 제약 조건(Constraints): PostgreSQL에서는 제약 조건을 사용하여 데이터 무결성을 보장할 수 있다. 예를 들어 Primary Key(기본 키), Foreign Key(외래 키), Unique Key(고유키), Check Constraint(검사 제약 조건) 등을 설정하여 정확하고 일관된 데이터 입력과 수정을 적용할 수 있다.
- 인덱싱(Indexing): PostgreSQL은 다양한 인덱스 기능을 제공하여 검색 성능을 최적화할 수 있다. B-트리 인덱스(B-tree Index), 해시 인덱스(Hash Index), GiST(Generic Search Tree) 인덱스 등 다양한 유형의 인덱스를 생성하여 원하는 검색 작업에 최적화된 방식으로 접근할 수 있다.
- 저장 프로시저와 함수: PostgreSQL에서는 저장 프로시저와 함수를 작성하여 복잡한 로직 및 계산 작업을 수행할 수 있다. PL/pgSQL과 같은 내부 언어뿐만 아니라 Python, JavaScript 등 외부 언어도 사용할 수 있는 확장 가능한 프로그래밍 인터페이스를 제공한다. 이를 활용하여 재사용 가능한 코드와 비즈니스 로직을 캡슐화하고 성능을 개선할 수 있다.
PostgreSQL 와 VectorDB 비교
PostgreSQL과 VectorDB는 다음 4가지 측면으로 나누어 비교해 볼 수 있다.
- 사용 사례: PostgreSQL은 트랜잭션과 분석을 포함한 다양한 애플리케이션에 적합한 범용 RDBMS이다. 그러나 VectorDB는 분석 처리에 특화되어 있기 때문에, 트랜잭션 처리에는 적합하지 않을 수 있다. ACID 속성 부족, 트랜잭션 오버헤드, 락과 충돌 등의 이유로 인해 데이터 무결성이 보장되어야 하는 애플리케이션에서는 아직까지 VectorDB가 많은 개선이 필요하다.
- 성능: VectorDB는 고차원 데이터 처리를 위해 설계된 벡터 스토리지와 벡터화 연산 기능 활용하여 고차원 데이터 분석 시나리오에서 우수한 성능을 발휘한다. PostgreSQL은 성능 면에서 우수하지만, Vector를 활용해야 하는 일부 시나리오에서는 VectorDB의 분석 성능을 따라잡지 못할 수 있다.
- CRUD 기능: PostgreSQL은 CRUD 기능을 통해 ACID(Atomicity, Consistency, Isolation, Durability) 트랜잭션 속성을 준수하여 데이터의 일관성과 안정성을 보장한다. 때문에, 데이터 무결성이 중요한 애플리케이션에 활용할 수 있기에 범용성이 좋다. 반면, VectorDB는 실제로 생성, 업데이트, 삭제 작업을 위해 설계되지 않았다. 읽기 작업의 경우, 지속성과 검색을 위해 먼저 데이터를 벡터화하고 색인화 해야한다. VectorDB는 벡터 데이터를 수집하고, 효율적인 유사도 검색을 위해 인덱싱하고, 벡터 유사도에 따라 가장 가까운 이웃을 쿼리하는 데 주안점을 두어 설계했다.
- 인기도 및 생태계: PostgreSQL은 광범위한 도구, 라이브러리 및 플러그인을 사용할 수 있는 대규모 활발한 사용자 커뮤니티를 보유하고 있다. 반면, VectorDB는 상대적으로 새로운 기술로서 생태계가 아직 제한적이기에 기술에 대한 레퍼런스 정보가 한정적일 수 있다.
PostgreSQL은 다양한 애플리케이션에 적합한 범용 RDBMS로 널리 사용되며, 트랜잭션과 분석을 포함한 다양한 기능을 제공한다. 반면에 VectorDB는 분석 워크로드에 특화되어 있으며, 특정 성능 요구와 벡터 데이터 처리를 필요로 하는 시나리오에서 유용한 선택이 될 수 있다.
Apache AGE

시나리오 설명에 앞서 vector 데이터를 적재하고 분석할 데이터베이스에 대한 이야기를 해보고자 한다. Apache AGE는 PostgreSQL를 그래프 데이터베이스 관점으로 활용할 수 있도록 하는 PostgreSQL 익스텐션이다. AGE는 A Graph Extension의 머리글자이며, PostgreSQL의 다중 모델 데이터베이스 포크인 Bitnine의 AgensGraph에서 영감을 받았다.
데이터베이스 내부에 관계형 및 그래프 데이터 모델을 모두 처리하는 단일 저장소를 만들어 사용자가 그래프 쿼리언어인 OpenCypher와 함께 표준 ANSI SQL을 사용할 수 있어 RDB 접근 방식과 GDB 접근 방식 모두 활용할 수 있다는 점에서 범용성이 넓다 라는 장점을 가지고 있다.
하지만, 앞서 언급한 바와같이 postgresql 은 고차원 데이터인 벡터를 관리하고 활용할 수 있는 기능이 없기 때문에, 이를 보완하고자 postgresql 익스텐션인 ‘pgvector’를 설치하여, 호환사용해보고자 한다.
postgresql , AGE, pgvector를 호환해서 사용한다면, 통해 관계형 데이터(relation data) , 그래프 데이터(graph data) 그리고 벡터 데이터(vector data)를 모두 활용할 수 있기에, postgresql 장점인 트랜잭션 , 무결성 지원과 VectorDB의 장점인 벡터 데이터 분석 및 관리를 혼용하여 애플리케이션에 적용할 수 있다.
Application overview

EDA
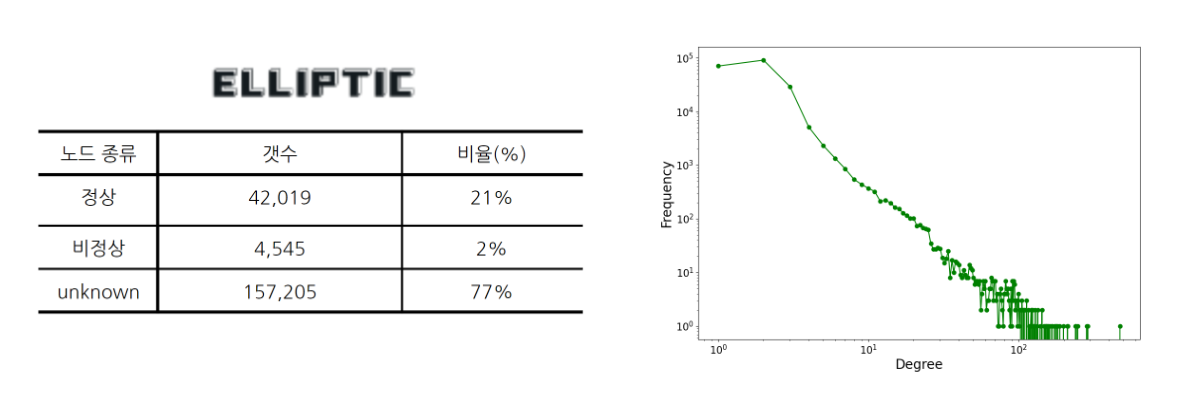
데이터는 ELLIPTIC 활용하였으며, 그래프 형태를 띈다. 노드는 거래를 나타내고, 에지는 한 거래와 다른 거래 사이의 가상화폐를 주고받음을 의미한다. 비정상 노드의 비율 2%는 정상 unknown에 비해 상당히 적은 수의 데이터를 보이고 있다.
그래프 구조 분석 결과 멱함수 분포를 띄고 있다. 멱함수 분포를 띈다는 것은 소수 거래 노드가 매우 큰 크기 또는 빈도를 가지면서, 대다수의 데이터 포인트는 상대적으로 작은 크기 또는 빈도를 가진다는 것을 의미한다. 흔히 말하는 빈익빈부익부 현상 또한 멱함수 분포를 띄고 있다 라고 할 수 있다.
Embedding
임베딩은 데이터를 컴퓨터가 읽기 쉽게 정량화 하는 기술을 의미한다. 기존 데이터 분포와 컴퓨터가 읽기 쉽게 변환하여 나타난 분포간 오차가 적게끔 유도하는게 임베딩 기술의 핵심이라 할 수 있다.
그래프 관점으로 접근하기 위해, 그래프 임베딩 모델으로 유명한 GCN(Graph Convlution Network)를 활용했다. GCN은 그래프 구조에서 노드와 이웃 노드들의 정보를 학습하여 노드의 특징을 업데이트하는 기술로, 그래프 데이터에 대해 효과적인 기계 학습 방법들 중 하나이다. 이를 통해 노드 간의 관계를 고려하여 복잡한 그래프 데이터에서 패턴을 추출하고 예측하는 데 활용한다.

임베딩 값을 활용하기 전, 해당 모델이 임베딩을 잘 수행했는지 점검해보기 위해, 예측 지표인 오차 행렬(Confusion Matrix) 과 Accuracy 와 loss를 나타낸 차트를 살펴보고자 한다. 오차 행렬은 학습을 통한 예측 성능 측정하기 위해 예측 값과 실제 값을 비교하기 위한 표다. 이를 통해 정확도, 정밀도, 재현도, F1 Score 를 확인할 수 있다. 각 지표들의 의미는 다음과 같다.
- 정확도(Accuracy): 전체 예측 중 올바르게 예측한 비율을 나타낸다.
- 정밀도(Precision): 양성으로 예측한 샘플 중 실제로 양성인 샘플의 비율을 나타낸다.
- 재현율(Recall): 실제 양성인 샘플 중 모델이 올바르게 양성으로 예측한 샘플의 비율을 나타낸다.
- F1 Score: 데이터가 불균형할 때 주로 쓰이는 지표로써, 정밀도과 재현율의 조화 평균값으로 계산된다.
포스팅에서 활용한 데이터셋은 합법 거래와 불법 거래의 비율이 각각 21% , 2% 정도의 불균형한 분포를 띄는 데이터셋 이기에, 이를 반영한 F1 score를 측정하는게 성능 지표 확인 측면에서 합리적이라 판단하여, 성능에 대한 평가 지표로 활용했다.
F1-score 결과 96% 수치를 보였으며, 이는 합법 거래와 불법 거래를 구분할 수 있는 성능이 96%라는 것으로도 볼 수 있기에 준수한 수치를 보인다 라고도 해석할 수 있다.
또한, 학습이 진행이 잘 되는지 확인하기 위해 모델 학습 과정을 기록한 우측 차트에서는 손실값과 정확도가 반비례하는 관계를 보이며, 학습 과정 또한 이상 없이 잘 진행 됐음을 관찰할 수 있다.
Vector load
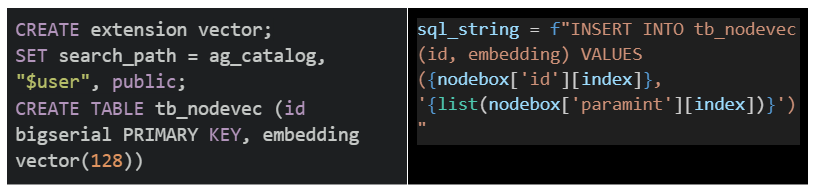
그림6은 임베딩 과정을 통해 추출한 128 고차원 데이터를 데이터 베이스에 적재하는 쿼리문과 코드다. 기존 AGE 는 vector라는 데이터 타입이 존재하지 않기에, pgvector 확장 모듈을 설치해야 vector 타입을 활용할 수 있다. pgvector 의 익스텐션 명은 vector 이며 데이터베이스 내에서 간단한 쿼리문을 통해 설치할 수 있다. 설치 후, vector 값을 담기 위한 테이블을 만든다. 이후, 앞서 추출한 고차원 임베딩값(데이터)을 vector 타입으로 테이블에 적재한다. 이를 통해 테이블에서 vectordb 처럼 vector 값을 관리 및 분석할 수 있게 된다.
Similarity search

불법 거래와 불법 거래 가능성이 있는 거래를 도출하기위해 기존 불법 거래와 유사한 거래들을 조회한다. 쿼리문에 ‘0’을 조건으로 두어, ‘0’에 해당하는 거래들만을 도출한다. 이때, ‘0’는 위험 거래로 지정된 거래 레이블을 의미한다. 샘플로 추출된 10개의 거래 리스트 중 본 시나리오 에서는 ‘34484’ 거래를 기반으로 어떻게 vector를 활용하여, 불법 거래 가능성이 있는 거래들을 탐지해본다.
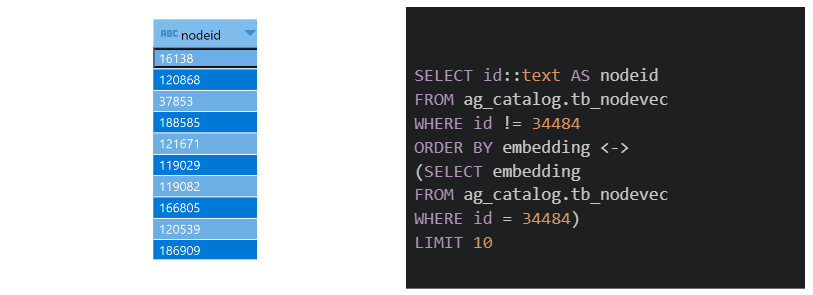
‘34484’ 거래 임베딩 값 기반 가장 유사한 10개의 값을 도출한 결과와 쿼리이다. LIMIT 을 통해 유사한 몇개의 값을 가져올지 지정해줄 수 있다 또한, <-> 와 같은 기호를 통해 어떤 유사도 기준으로 비교할지에 대해서도 설정할 수 있다. pgvector에서 활용할 수 있는 거리 유사도 기준은 총 3개 distance(<->) , inner product(<#>) , cosine similarity(<=>) 가 있다. 본 시나리오에서는 유사도를 distance 기준으로 값을 도출한 결과, 16138 부터 186909 까지 총 10개의 거래 노드들을 발견했다.

앞서 유사도 검색을 통해 도출된 값 10개 거래들의 레이블을 살펴본 결과 주로 위험 거래와 거래에 대해 레이블링이 되어있지 않은 거래들로 이루어짐을 확인했다. 다시말해, 위험 거래들을 추출하기 위해 위험 거래인 ‘34484’ 를 기준으로 유사한 거래들을 탐지한 결과, ‘34484’와 유사한 위험 거래들이 잘 탐지되었음을 확인할 수 있다.
Pattern detection
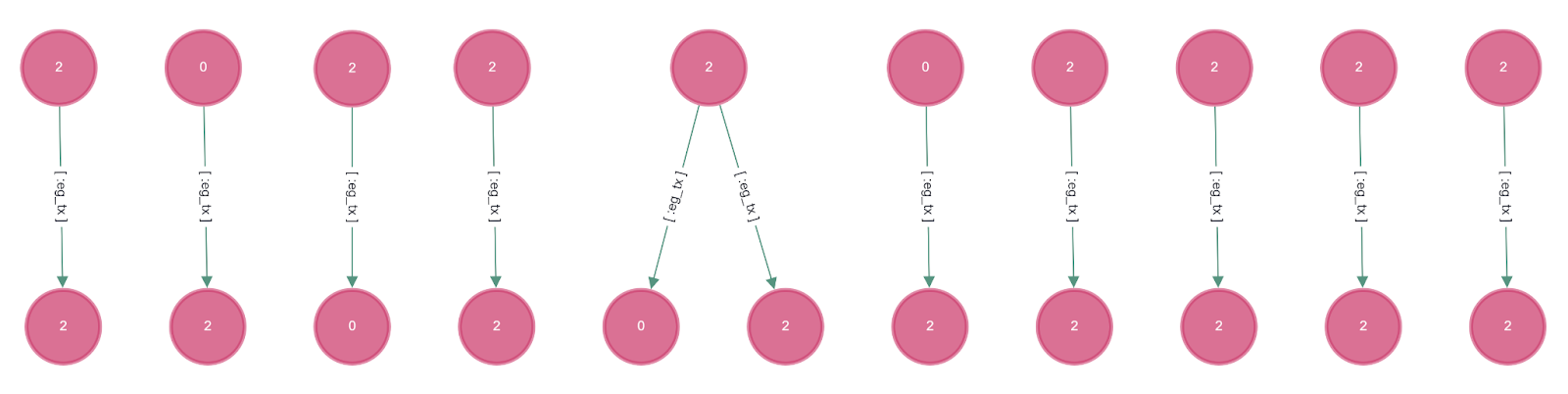
그림10은 유사도 검색을 통해 추출된 거래값들을 AGEviewer를 통해 시각화한 결과 그림이다. ‘1’ 라벨을 가진 노드인 정상 거래와는 연관이 없고, '0'과 '2' 라벨인 위험 거래 및 미확인 거래와 연관이 있는 거래 노드들만 추출되었음을 확인할 수 있다. 이때, 라벨링이 되어 있지 않은 미확인 거래에 대해 식별할 필요가 있을때, 위험 거래와 관계의 유무에 따라 위험 가능성을 가늠해볼 수 있으므로, 의심이 가는 잠재적 위험 거래군과 패턴을 발견하는데 활용할 수 있다.
결론
본 포스팅에서는 PostgreSQL과 VectorDB 데이터베이스의 개요와 장단점을 비교했다. PostgreSQL에 벡터 관리 기능을 확장 모듈인 pgvector을 통해 보완할 수 있음을 확인했고, pgvector의 벡터 유사도 검색 기능을 활용한 이상거래 탐지 시나리오를 살펴보았다. 관계에 대한 정의 및 탐지가 중요한 이상거래 탐지분야에서 관계에 특화된 모듈인 AGE와 pgvector를 함께 사용함으로써, Postgresql에서 직접 유사성 검색을 하여 패턴을 발견하고 데이터 해석을 용이하게 할 수 있음을 확인했다. 특히, 이상 거래탐지에서 중요한 분야들인 그레이 리스팅과 트래블룰 등에서 주로 쓰이는 관계 분석에 유사성 검색 기능을 접목하여 혼용할 수 있기에, 기존보다 더욱 강력한 이상 거래탐지 시스템을 구축할 수 있다.
참고자료
2. https://github.com/pgvector/pgvector
3. https://www.aitimes.com/news/articleView.html?idxno=150787
4. https://db-engines.com/en/ranking_trend
5. M. Weber, G. Domeniconi, J. Chen, D. K. I. Weidele, C. Bellei, T. Robinson, C. E. Leiserson, "Anti-Money Laundering in Bitcoin: Experimenting with Graph Convolutional Networks for Financial Forensics", KDD ’19 Workshop on Anomaly Detection in Finance, August 2019, Anchorage, AK, USA.
6.https://www.singlestore.com/blog/choosing-a-vector-database-for-your-gen-ai-stack/
7. https://www.pinecone.io/learn/vector-database/
글 : 정이태 선임 ( 비트나인 글로벌 사이언스팀 )
'POSTGRESQL' 카테고리의 다른 글
| PostgreSQL Architecture (0) | 2023.09.02 |
|---|---|
| PostgreSQL의 장점과 단점 (0) | 2023.09.02 |
| PostgreSQL - LogCollector (0) | 2023.08.29 |
| PostgreSQL - Vacuum의 A to the Z (0) | 2023.08.29 |
| PostgreSQL성능진단표준가이드 (0) | 2023.08.29 |