
작성자: 서준섭 과장_DB 기술센터-DB Tech팀
PostgreSQL 트러블슈팅 가이드: Slow Query
PostgreSQL에서 slow query는 전반적인 시스템 성능에 큰 악영향을 줄 수 있습니다.
먼저 slow query는 데이터베이스 서버의 CPU와 메모리 자원을 과도하게 소모하여 다른 쿼리들의 실행을 방해할 수 있습니다. 이는 전체적인 응답 시간 지연으로 이어져, 사용성을 크게 저하시킬 수 있습니다.
또한 slow query는 데이터베이스 연결 수를 급격히 증가시켜 리소스 고갈로도 이어질 수 있습니다. 이 경우 새로운 연결 요청이 지연되거나 거부되어 전체적인 서비스 가용성이 떨어질 수 있습니다.
더불어 데이터베이스 로그 파일의 용량을 빠르게 증가시켜 디스크 공간 문제도 야기할 수 있습니다. 이는 결국 데이터베이스 백업 및 복구 작업에도 악영향을 줄 수 있습니다.
결국 slow query는 데이터베이스 서버의 리소스 고갈, 사용성 및 서비스 가용성 저하, 디스크 공간 문제 등 다양한 측면에서 시스템 성능을 크게 저하시킬 수 있습니다. 따라서 이에 대한 지속적인 모니터링과 적극적인 튜닝이 필요합니다.
본 아티클은 PostgreSQL에서 slow query를 어떻게 확인하고 해결하는지에 대해 소개하겠습니다.
Slow Query 확인 방법
1. pg_stat_activity 모니터링
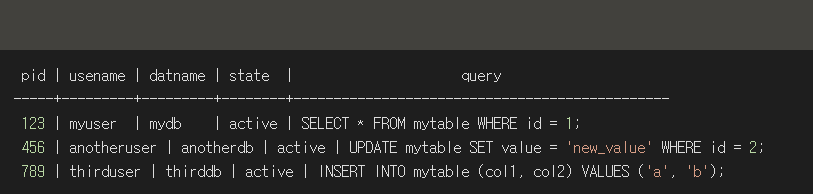
지난 1부에서 소개한 pg_stat_activity 뷰를 통해 현재 실행 중인 쿼리를 실시간으로 모니터링할 수 있습니다. 이 뷰에는 각 세션의 PID, 사용자 이름, 접속된 데이터베이스 이름, 현재 실행 중인 쿼리 등의 정보가 포함되어 있습니다.
예를 들어, 다음과 같은 쿼리를 통해 현재 실행 중인 쿼리의 목록을 얻을 수 있습니다.


2. EXPLAIN 명령어 사용
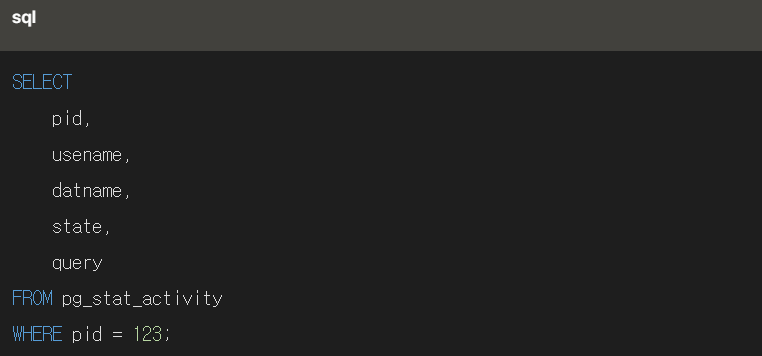
쿼리의 실행 계획을 확인하기 위해 EXPLAIN 명령어를 사용합니다. 실행 계획을 통해 쿼리가 어떤 방식으로 실행되는지, 어떤 인덱스를 사용하는지, 어떤 테이블 스캔을 수행하는지 등을 알 수 있습니다.
다음과 같은 쿼리를 통해 실행 계획을 확인할 수 있습니다.


또다른 예시를 통해 EXPLAIN ANALYZE로 실제 쿼리 실행 시간과 실행 계획을 동시에 확인할 수 있습니다.

결과:
Seq Scan on large_table (cost=0.00..4456.00 rows=1000 width=100) (actual time=120.235..1200.345 rows=1000 loops=1)
Filter: ((column1 = 'some_value'::text) AND (column2 ~~ '%some_pattern%'::text))
Rows Removed by Filter: 9000
Total runtime: 1201.234 ms
위 결과에서는 실제 실행 시간(actual time), 실제 반환된 행 수(actual rows) 등의 정보도 확인할 수 있고, 실행 결과와 함께 소요된 시간도 보여줍니다. 해당 예시에서는 약 1.2초가 소요된 것을 알 수 있습니다.
Slow query를 해결할 수 있는 방법은 많겠지만 하나의 예시로 index를 생성하고 쿼리를 다시 실행하여 소요된 시간을 줄이는 방법을 표현해보겠습니다.
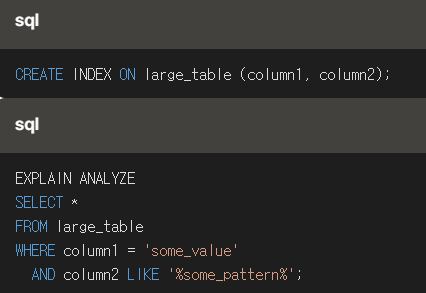
결과:
Index Scan using large_table_column1_column2_idx on large_table (cost=0.29..8.30 rows=1 width=100) (actual time=0.029..0.041 rows=1 loops=1)
Index Cond: ((column1 = 'some_value'::text) AND (column2 ~~ '%some_pattern%'::text))
Total runtime: 0.075 ms
Large_table에 Index를 추가하여 total runtime을 줄일 수 있었습니다.
사용자는 위와 같이 쿼리의 성능 문제를 파악하고, 적절한 최적화 방법을 찾아서 slow query를 해결할 수 있습니다.
3. 쿼리 프로파일링
쿼리 프로파일링 도구를 사용하면 쿼리 실행 시간, CPU 및 메모리 사용량 등을 더욱 세밀하게 분석할 수 있습니다. 대표적인 도구로는 pg_stat_statements가 있습니다. 이는 각 쿼리의 실행 횟수, 총 실행 시간, 평균 실행 시간 등을 수집하여 성능 분석에 도움을 줍니다.

가장 오래 걸리는 쿼리, 가장 많이 실행된 쿼리, 가장 많은 CPU를 사용한 쿼리 등을 정확하게 파악할 수 있도록 지원하는 도구를 활용하여 쿼리 성능의 병목 지점을 더 정확하게 파악해보시기 바랍니다.
4. 로그 분석
PostgreSQL에서는 다양한 정보를 로그 파일에 기록합니다. 이 로그 파일에는 쿼리 실행 시간, 실행 계획, 에러 메시지 등이 포함되어 있습니다. 이를 통해 사용자는 성능 문제를 일으키는 쿼리를 쉽게 파악할 수 있습니다.
로그 파일의 위치는 postgresql.conf 파일에서 설정할 수 있습니다. 기본적으로는 데이터 디렉터리 내에 위치하지만, 필요에 따라 별도의 디렉터리를 지정할 수 있습니다.
Slow query 로그를 활성화하려면 다음과 같은 설정을 추가할 수 있습니다:

로그 파일은 데이터 디렉터리 내의 pg_log 폴더에 생성되며, 다음과 같은 형식으로 기록됩니다:
2023-06-20 10:30:45.123 UTC [123] LOG: duration: 1234.567 ms statement: SELECT * FROM users WHERE email = 'example@example.com';
위 설정에서 log_min_duration_statement는 쿼리 실행 시간이 1초 이상인 경우에만 로그에 기록하도록 합니다. 이 값은 상황에 따라 조절할 수 있습니다.
log_directory는 로그 파일이 저장될 디렉터리를 지정하며, log_filename은 로그 파일의 이름 형식을 정의합니다. 이 예시에서는 날짜와 시간 정보가 포함된 파일명을 사용하고 있습니다. 이렇게 설정된 로그 파일을 분석하면 다음과 같은 정보를 얻을 수 있습니다:
1. 쿼리 실행 시간: 로그 파일에 기록된 실행 시간을 통해 slow query를 식별할 수 있습니다.
2. 실행 계획: 로그에 포함된 실행 계획 정보를 통해 쿼리의 성능 병목 지점을 파악할 수 있습니다.
3. 에러 메시지: 로그에 기록된 에러 메시지를 통해 쿼리 실행 시 발생한 문제를 확인할 수 있습니다.
이러한 정보를 종합적으로 분석하여 사용자는 성능 문제를 일으키는 쿼리를 식별하고, 적절한 최적화 방법을 찾아 적용시킬 수 있습니다.
3부에 계속 되는 Troubleshooting 가이드
2부 아티클에서는 PostgreSQL에서 slow query가 시스템에 끼치는 악영향을 알아봤고 문제를 해결하기 위해 확인하는 방법을 알아봤습니다.
이어지는 3부 troubleshooting 가이드에서는 lock에 대해 전반적으로 알아보고자 합니다. Lock은 데이터베이스 동시성 제어를 위해 필수적으로 사용되는 기능인데, 관리가 제대로 이루어 지지 않으면 다양한 문제가 발생할 수 있습니다. 어떤 문제가 어떤 결과를 초래하는지, 그리고 이에 대한 troubleshooting 방법을 간략하게 알아보겠습니다.

'POSTGRESQL > 단편' 카테고리의 다른 글
| PostgreSQL, pg_rewind(Failback) (0) | 2024.07.02 |
|---|---|
| PostgreSQL 글로벌 컨트리뷰터와의 기술 인터뷰_feat. 최신 PG 17버전 (0) | 2024.06.27 |
| PostgreSQL 성능 저하 Troubleshooting 가이드-1부- (0) | 2024.06.24 |
| 누가 Vacuum을 방해하는가? (0) | 2024.06.17 |
| 스타트업을 위한 안정적인 DBMS관리 노하우 (0) | 2024.06.03 |